Software Development
Our portfolio of tools and services for FAIR metadata grows constantly and we continuously develope our tools and publish new releases. With these tools we want to facilitate the generation of structured metadata within scientific workflows and allow to use the benefits of metadata annotation during the reserach process. Here you can find a selection of some of our current projects with short descriptions – please follow the links or contact us for further information.

DIRSCHEMA is a metadata specification and validation tool that enforces structural metadata requirements in local datasets. Research groups can use DirSchema during dataset preparation in order to harmonize and enrich datasets across groups.
https://github.com/Materials-Data-Science-and-Informatics/dirschema
PIDA is a service providing unique persistent URLs (PURLs) for referencing digital assets on the web to ensure that they remain findable and can be accessed reliably by both humans and machines. PIDA associates the PID with the actual URL/IRI and returns that location on the web to the client when requested. The client can then complete the transaction in a typical fashion. Also PIDA allows content negotiation for use in semantic applications (e.g. ontologies). We are committed to maintain and offer PIDA as a service for the next 10+ years.
https://purls.helmholtz-metadaten.de/

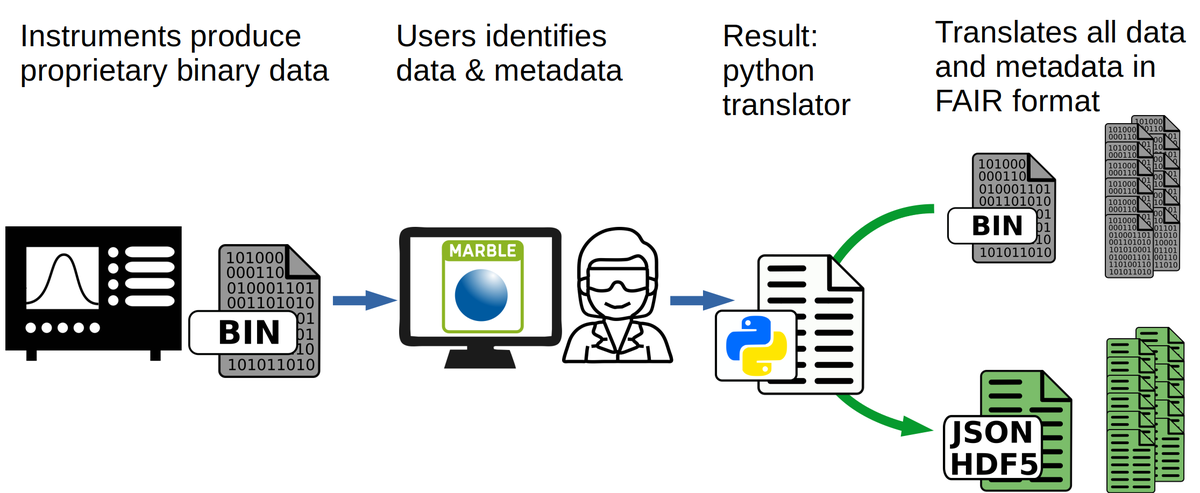
MARBLE: Raw and metadata from scientific instruments is often stored in proprietary binary files. Easy access to both kinds of data differs depending on various factors like vendors, instrument generation etc. MARBLE is a software tool which, via a GUI, will allow scientists to decipher metadata and raw data from proprietary binary files. The tool is currently under development and will eventually support the creation and access to converters that store data, alongside meta data, for different kinds of proprietary file formats.
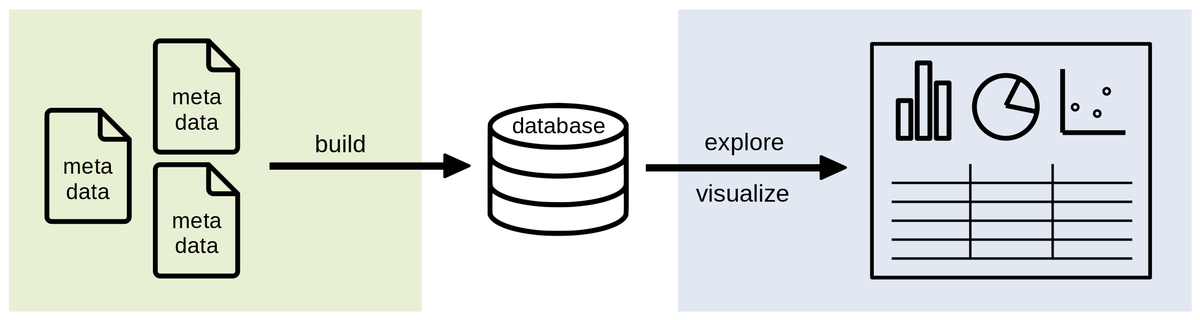
BEAVERDAM: Collecting metadata during experiments is only beneficial if it can be used later. We are developing BEAVERDAM (Build, Explore, And Visualize ExpeRiment DAtabases of Metadata) as a tool to interactively explore metadata, and testing it on a dataset from neuroscience experiments. Users will be able to combine existing structured metadata from multiple experiments into a database and use BEAVERDAM to interactively browse and visualize metadata in this database (i.e. to identify experiments that meet specific criteria) thereby informing further analyses.

METADOR provides a web-based structured submission interface for systematically sharing structured metadata alongside research data in direct collaborations. Use Metador to (1) predefine the metadata requirements for a specific dataset, (2) validate entered metadata against a schema, (3) associate your research data files with structured (JSON) metadata. We are currently developing Metador into a platform for bi-directional data exchange.
https://github.com/Materials-Data-Science-and-Informatics/metador